Machine Learning: Algorithms and Guarantees:

Reinforcement Learning with Non-Linear Function of Multiple Objectives:
Reinforcement Learning algorithms such as DQN owe their success to Markov Decision Processes, and the fact that maximizing the sum of rewards allows using backward induction and reduce to the Bellman optimality equation. However, many real-world problems require optimization of an objective that is non-linear in cumulative rewards for which dynamic programming cannot be applied directly. For example, in a resource allocation problem, one of the objectives is to maximize long-term fairness among the users. We notice that when the function of the sum of rewards is considered, the problem loses its Markov nature. In this theme, we propose novel model-based and model-free algorithms with provable guarantees. As shown alongside, for a network traffic optimization problem, the proposed Actor-Critic (IFRL AC) and Policy Gradient (IFRL PG) approaches significantly outperform the standard approaches that do not explicitly account for non-linearity.
Constrained Reinforcement Learning:
Many engineering problems have constraints, e.g., power, bandwidth, amount of movement, etc. In the presence of constraints, the decision making is challenging since the optimal policy may not longer be deterministic. On this direction, we aim to come up with efficient algorithms with provable guarantees that can handle constraints in decision making.
- Ather Gattami, Qinbo Bai, and Vaneet Agarwal, "Reinforcement Learning for Multi-Objective and Constrained Markov Decision Processes," in Proc. AISTATS, Apr 2021 (29.8% acceptance rate, 455/1527)
- Qinbo Bai, Vaneet Aggarwal, Ather Gattami, "Provably Efficient Model-Free Algorithm for MDPs with Peak Constraints," Jan 2021
Combinatorial Bandits:
Exploiting structure in the data across multiple dimensions can lead to efficient techniques for efficient sampling and fingerprinting. The figure alongside shows different network service attributes dependence on time, spatial locations and data service quality measurements thus motivating tensor structure. Further, the map shows the received signal strength in indoor has spatial dependence and the signals from different APs are correlated and thus adaptive sampling can reduce fingerprints needed for localization.
- Mridul Agarwal, Vaneet Aggarwal, Christopher J. Quinn, and Abhishek Umrawal, "DART: aDaptive Accept RejecT for non-linear top-K subset identification," in Proc. AAAI, Feb 2021 (21% acceptance rate, 1692/7911).
- Mridul Agarwal, Vaneet Aggarwal, Christopher J. Quinn, and Abhishek Umrawal, "Stochastic Combinatorial Bandits with Linear Space and Non-Linear Feedback," in Proc. ALT, Mar 2021 (PMLR 132:306-339, 2021.) (29.3% acceptance rate, 46/157).
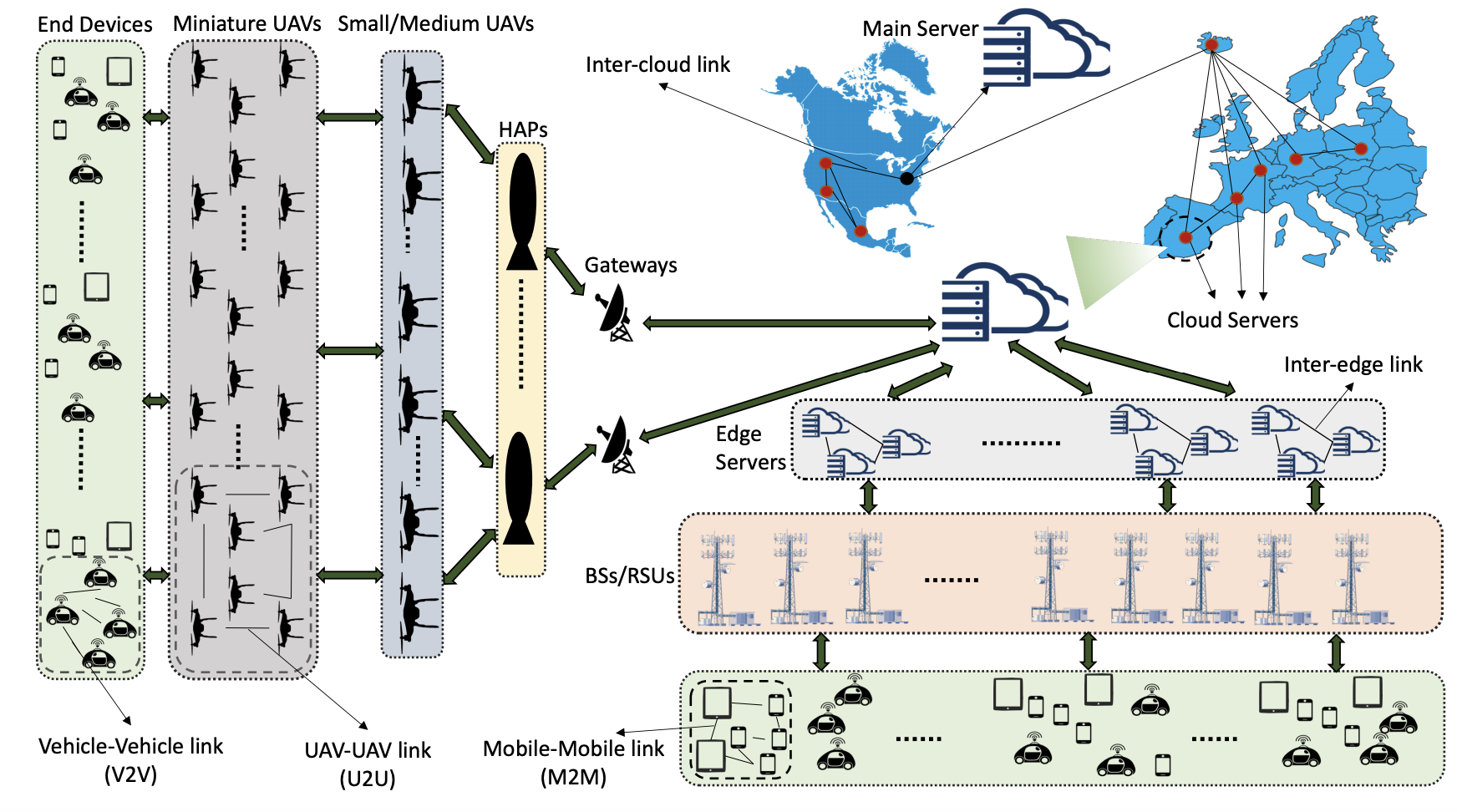
Federated and Fog Learning:
Federated learning has generated significant interest, with nearly all works focused on a "star" topology where nodes/devices are each connected to a central server. We migrate away from this architecture and extend it through the network dimension to the case where there are multiple layers of nodes between the end devices and the server. Specifically, we develop multi-stage hybrid federated learning (MH-FL), a hybrid of intra- and inter-layer model learning that considers the network as a multi-layer cluster-based structure, each layer of which consists of multiple device clusters. MH-FL considers the topology structures among the nodes in the clusters, including local networks formed via device-to-device (D2D) communications. It orchestrates the devices at different network layers in a collaborative/cooperative manner (i.e., using D2D interactions) to form local consensus on the model parameters, and combines it with multi-stage parameter relaying between layers of the tree-shaped hierarchy.
- Seyyedali Hosseinalipour, Sheikh Shams Azam, Christopher G. Brinton, Nicolo Michelusi, Vaneet Aggarwal, David J. Love, Huaiyu Dai, "Multi-Stage Hybrid Federated Learning over Large-Scale Wireless Fog Networks," Aug 2020
- Seyyedali Hosseinalipour, Christopher G. Brinton, Vaneet Aggarwal, Huaiyu Dai, and Mung Chiang, "From Federated Learning to Fog Learning: Towards Large-Scale Distributed Machine Learning in Heterogeneous Networks," Accepted to IEEE Communications Magazine, Sept 2020.
- Anis Elgabli, Jihong Park, Amrit S. Bedi, Chaouki Ben Issaid, Mehdi Bennis, and Vaneet Aggarwal, "Q-GADMM: Quantized Group ADMM for Communication Efficient Decentralized Machine Learning," IEEE Transactions on Communications, vol. 69, no. 1, pp. 164-181, Jan 2021
- Anis Elgabli, Jihong Park, Amrit S. Bedi, Mehdi Bennis, and Vaneet Aggarwal,"GADMM: Fast and Communication Efficient Framework for Distributed Machine Learning," Journal of Machine Learning Research, Mar 2020.
- Anis Elgabli, Jihong Park, Amrit S. Bedi, Mehdi Bennis, and Vaneet Aggarwal, "Q-GADMM: Quantized Group ADMM for Communication Efficient Decentralized Machine Learning," in Proc. ICASSP, May 2020.
- Anis Elgabli, Jihong Park, Amrit Bedi, Mehdi Bennis, and Vaneet Aggarwal, "Communication Efficient Framework for Decentralized Machine Learning," in Proc. CISS, Mar 2020
Parallel Reinforcement Learning:
We consider M parallel reinforcement learning agents, and wish to achieve the same regret as if they are fully collaborative, while communicating for only logarithmic number of rounds. Though seemingly impossible, we show that even with such limited communication, optimal regret bounds can be achieved. For the special case of bandits, we show that not only is the amount of communication rounds logarithmic in the time, the agents only need to share the best arm index thus achieving better privacy among agents.
Gaussian Process Bandits:
Bayesian optimization is a framework for global search via maximum a posteriori updates rather
than simulated annealing, and has gained prominence for decision-making under uncertainty. In
this work, we cast Bayesian optimization as a multi-armed bandit problem, where the payoff
function is sampled from a Gaussian process (GP). Further, we focus on action selections via upper
confidence bound (UCB) or expected improvement (EI) due to their prevalent use in practice. We derive sublinear regret bounds of GP bandit algorithms up to factors depending on the
compression parameter �for both discrete and continuous action sets. Experimentally, we observe state of the art accuracy and complexity tradeoffs for GP bandit algorithms applied to global optimization, suggesting the merits of compressed GPs in bandit
settings.
- Amrit Singh Bedi, Dheeraj Peddireddy, Vaneet Aggarwal, and Alec Koppel, "Sublinear Regret and Belief Complexity in Gaussian Process Bandits via Information Thresholding," Submitted to JMLR, Dec 2020 (under revision).
- Amrit Singh Bedi, Dheeraj Peddireddy, Vaneet Aggarwal, and Alec Koppel, "Efficient Large-Scale Gaussian Process Bandits by Believing only Informative Actions," in Proc. L4DC, Jun 2020.
Mean-Field Games:
We consider a multi-agent Markov strategic interaction over an infinite horizon where agents can be of multiple types. We model the strategic interaction as a mean-field game in the asymptotic limit when the number of agents of each type becomes infinite. Each agent has a private state; the state evolves depending on the distribution of the state of the agents of different types and the action of the agent. Each agent wants to maximize the discounted sum of rewards over the infinite horizon which depends on the state of the agent and the distribution of the state of the leaders and followers. We seek to characterize and compute a stationary multi-type Mean field equilibrium (MMFE) in the above game. We characterize the conditions under which a stationary MMFE exists. We also extend the problem to leader-follower setup with multiple leaders and multiple followers.
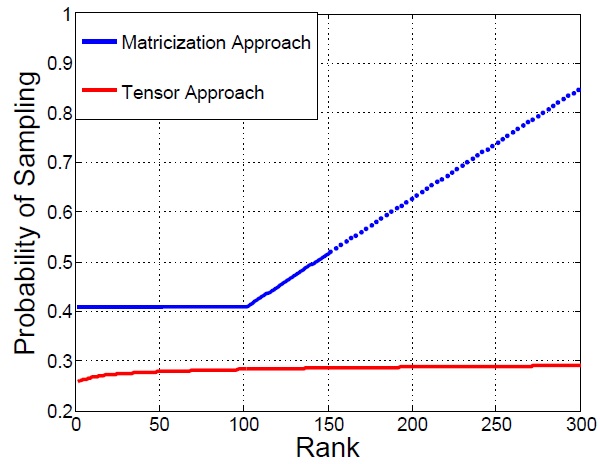
Tensor Networks:
Tensors are generalizations of vectors and matrices; a vector is a first-order tensor and a matrix is a second-order tensor. Most of the data around us are better represented with multiple orders to capture the correlations across different attributes. For example, a color image can be considered as a third-order tensor, two of the dimensions (rows and columns) being spatial, and the third being spectral (color), while a color video sequence can be considered as an order four tensor, time being the fourth dimension besides spatial and spectral. Similarly, a colored 3-D MRI image across time can be considered as an order five tensor. Exploiting additional structure leads to better embedding algorithms for subspace analysis and the elements needed for data completion (as shown alongside).
- M. Ashraphijuo, X. Wang, and V. Aggarwal, "Fundamental sampling patterns for low-rank multi-view data completion," Pattern Recognition, vol. 103, Jul 2020.
- X. Liu, S. Aeron, V. Aggarwal, and X. Wang, "Low-tubal-rank Tensor Completion using Alternating Minimization," IEEE Transactions on Information Theory, vol. 66, no. 3, pp. 1714-1737, March 2020.
- W. Wang, Y. Sun, B. Eriksson, W. Wang, and V. Aggarwal, "Wide Compression: Tensor Ring Nets," in Proc. CVPR, Jun 2018 (29% acceptance rate).
- W.Wang, V. Aggarwal, and S. Aeron, "Efficient Low Rank Tensor Ring Completion," in Proc. ICCV, Oct 2017 (28.9% acceptance rate).
- W.Wang, V. Aggarwal, and S. Aeron, "Unsupervised Clustering Under The Union of Polyhedral Cones (UOPC) Model," Pattern Recognition Letters, vol. 100, pp. 104-109, Dec 2017.
- M. Ashraphijuo, V. Aggarwal, and X. Wang, "Deterministic and Probabilistic Conditions for Finite Completability of Low-Tucker-Rank Tensor," IEEE Transactions on Information Theory, vol. 65, no. 9, pp. 5380-5400, Sept. 2019.
- W. Wang, V. Aggarwal, and S. Aeron, "Tensor Train Neighborhood Preserving Embedding," IEEE Transactions on Signal Processing, vol. 66, no. 10, pp. 2724-2732, May, 2018.
- M. Ashraphijuo, V. Aggarwal, and X. Wang, "On Deterministic Sampling Patterns for Robust Low-Rank Matrix Completion," IEEE Signal Processing Letters, vol. 25. no. 3, pp. 343-347, Mar 2018.
- M. Ashraphijuo, X. Wang, and V. Aggarwal, "Rank Determination for Low-Rank Data Completion," Journal of Machine Learning Research, vol. 18(98), pp. 1-29, Sept 2017.
- M. Ashraphijuo, X. Wang, and V. Aggarwal,"An approximation of the CP-rank of a partially sampled tensor," in Proc. Allerton, Oct 2017.
- M. Ashraphijuo, V. Aggarwal, and X. Wang, "A characterization of sampling patterns for low-tucker-rank tensor completion problem," in Proc. IEEE ISIT, Jun 2017.
- M. Ashraphijuo, X. Wang, and V. Aggarwal,"A characterization of sampling patterns for low-rank multi-view data completion problem," in Proc. IEEE ISIT, Jun 2017.
- V. Aggarwal, A. A. Mahimkar, H. Ma, Z. Zhang, S. Aeron, and W. Willinger, "Inferring Smartphone Service Quality using Tensor Methods," in Proc. 12th International Conference on Network and Service Management Oct-Nov, 2016.
- X. Liu, S. Aeron, V. Aggarwal, X. Wang, and M. Wu, "Adaptive Sampling of RF fingerprints for Fine-grained Indoor Localization," IEEE Transactions on Mobile Computing, vol. 15, no. 10, pp. 2411-2423, Oct. 2016.
- V. Aggarwal and S. Aeron, "A note on Information-theoretic Bounds on Matrix Completion under Union of Subspaces Model," in Proc. Allerton, Sept 2016.
- W.Wang, S. Aeron, and V. Aggarwal, "On deterministic conditions for subspace clustering under missing data," in Proc. IEEE ISIT, 2016.
- X. Liu, S. Aeron, V. Aggarwal, and X. Wang, "Low-tubal-rank Tensor Completion using Alternating Minimization," in Proc. SPIE Defense + Security, 2016.
- X. Liu, S. Aeron, V. Aggarwal, X. Wang, and M. Wu, "Tensor completion via adaptive sampling of tensor fibers: An application to efficient RF fingerprinting," in Proc. IEEE ICASSP, Mar 2016.
Home