Cloud and Storage Systems:
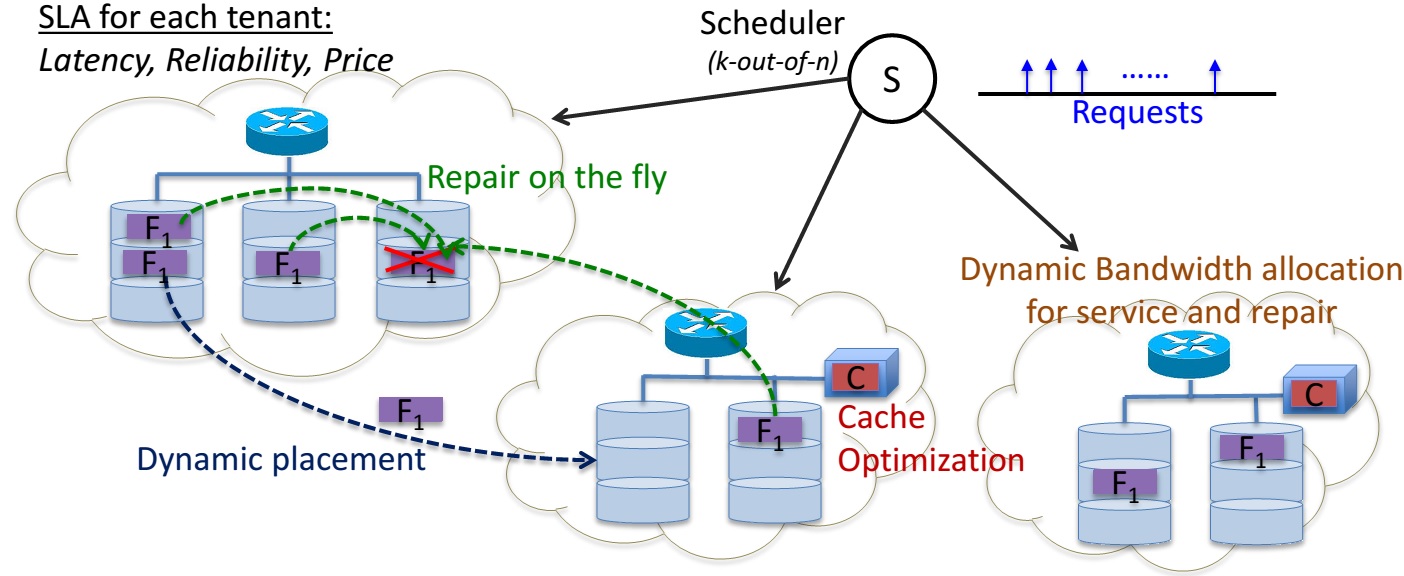
Erasure Codes in Distributed Storage for Effective Latency:
Modern distributed storage systems offer large capacity
to satisfy the exponentially increasing need of storage
space. They often use erasure codes to protect against disk and
node failures to increase reliability, while trying to meet the
latency requirements of the applications and clients. In order to meet these requirements, the code design, chunk placement and the chunk access (when client requests) need to be optimally found. We propose new solutions for joint latency cost tradeoff, and implement these solutions on Tahoe public grid, and AT&T Cloud Systems.
The figure alongside depicts the different key design attributes for a general cloud system that we are working towards for a vision of optimized dynamic storage system.
- Moonmoon Mohanty, Gaurav Gautam, Vaneet Aggarwal, and Parimal Parag, "Analysis of fork-join scheduling on heterogeneous parallel servers," Submitted to IEEE/ACM Transactions on Networking, Jul 2023 (under revision)
- V. Aggarwal and T. Lan, "Modeling and Optimization of Latency in Erasure-coded Storage Systems," Now Foundations and Trends in Communication and Information Theory, Vol. 18, No. 3, pp 380-525, Jul 2021.
- A. O. Alabbasi and V. Aggarwal, "TTL-cache: Taming Latency in Erasure-Coded Storage Through TTL Caching," IEEE Transactions on Network and Service Management, vol. 17, no. 3, pp. 1582-1596, Sept. 2020.
- A. O. Alabbasi, V. Aggarwal, and T. Lan, "TTLoC: Taming Tail Latency for Erasure-coded Cloud Storage Systems," IEEE Transactions on Network and Service Management, vol. 16, no. 4, pp. 1609-1623, Dec. 2019.
- Y. Zhang, A. Ghosh, V. Aggarwal, and T. Lan, "Tiered cloud storage pricing via two-stage, latency-aware bidding," IEEE Transactions on Network and Service Management, vol. 16, no. 1, pp. 176-191, March 2019.
- A. Alabbasi and V. Aggarwal, "Mean Latency Optimization in Erasure-coded Distributed Storage Systems," in Proc. Infocom Workshop (International Workshop on Cloud Computing Systems, Networks, and Applications (CCSNA)), Apr 2018.
- V. Aggarwal, J. Fan, and T. Lan, "Taming Tail Latency for Erasure-coded, Distributed Storage Systems," in Proc. IEEE Infocom, Jul. 2017.
- V. Aggarwal, Y.R. Chen, T. Lan, and Y. Xiang, "Sprout: A functional caching approach to minimize service latency in erasure-coded storage," IEEE/ACM Transactions on Networking, vol. 25, no. 6, pp. 3683-3694, Dec 2017.
- Y. Xiang, V. Aggarwal, T. Lan, and Y.R. Chen, "Differentiated latency in data
center networks with erasure coded �files through traffic engineering," Accepted to IEEE Transactions on Cloud Computing, Dec 2016.
- Y. Xiang, T. Lan, V. Aggarwal, and Y.R. Chen, "Optimizing Differentiated Latency in Multi-Tenant, Erasure-Coded Storage," IEEE Transactions on Network and Service Management, vol. 14, no. 1, pp. 204-216, March 2017.
- V. Aggarwal, Y.R. Chen, T. Lan, and Y. Xiang, "Sprout: A functional caching approach to minimize service latency in erasure-coded storage," in Proc. ICDCS, Jun. 2016.
- Y. Xiang, T. Lan, V. Aggarwal, and Y.R. Chen, "Multi-tenant Latency Optimization in Erasure-Coded Storage with Differentiated Services," in Proc. ICDCS, Jun-Jul. 2015.
- Y. Xiang, V. Aggarwal, Y.R. Chen, and T. Lan, "Taming latency in data center
networking with erasure coded files," in Proc. IEEE/ACM International Symposium on Cluster, Cloud
and Grid Computing, May 2015.
- Y. Xiang, T. Lan, V. Aggarwal, and R. Chen, "Joint Latency and Cost Optimization
for Erasure-coded Data Center Storage," IEEE/ACM Transactions on Networking, vol. 24, no. 4, pp. 2443-2457, Aug. 2016.
- Y. Xiang, T. Lan, V. Aggarwal, and R. Chen, "Joint Latency and Cost Optimization
for Erasure-coded Data Center Storage," ACM SIGMETRICS Performance Evaluation Review, Volume 42 Issue 2, Sep. 2014. (presented in Proc. IFIP, Oct. 2014)
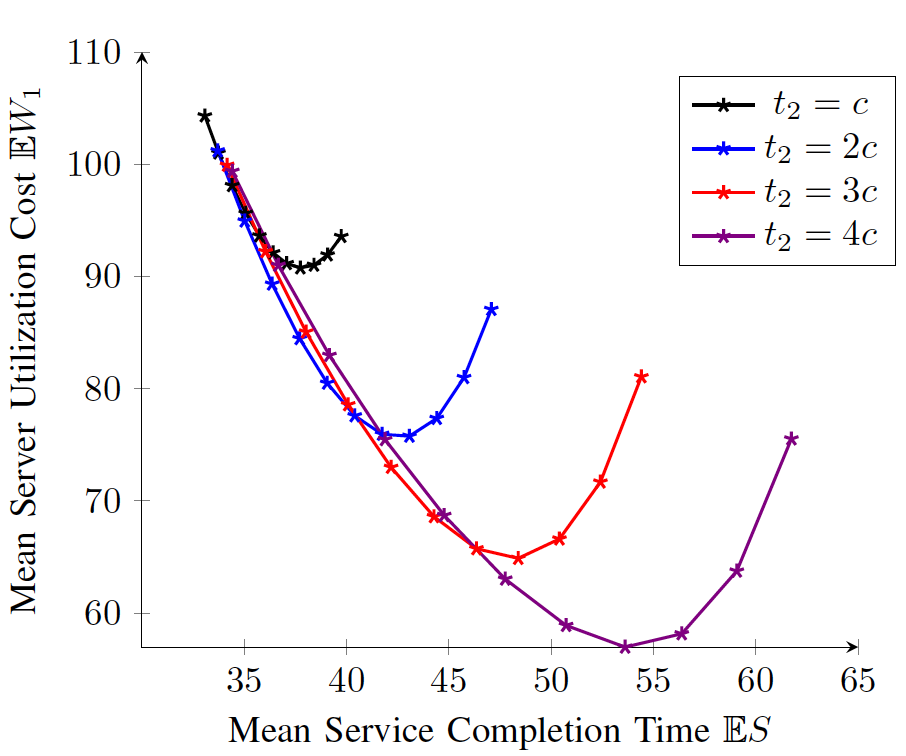
Straggler Management with Coding and Queueing Strategies:
The performance of large-scale distributed compute systems is adversely impacted by stragglers when the execution time of a job is uncertain. In order to manage stragglers, redundancy in the execution is essential. However, to optimize the cost of servers, all servers cannot be started in the beginning while a tiered strategy (also called multi-forking) is needed. The figure alongside shows the tradeoff between the service completion time and the server utilization cost for shifted exponential service time with different forking times and different number of initial servers. We consider such tradeoffs to determine parameters at which system should be operated. However, these parameters can influence the task sizes in the split of tasks over the servers since the straggler guarantees are needed. Multi-forking provides a flexibility that the results of some tasks could be seen before opening new tasks which decreases the execution times. Thus, the problem of efficient management of stragglers requires joint split of tasks (using coding-theoretic schemes) and well as the determination of system parameters using queueing-theoretic techniques that determine the tradeoff between the service completion time and the server utilization cost.
- A. Badita, P. Parag, and V. Aggarwal, "Single-forking of coded subtasks for straggler mitigation," IEEE/ACM Transactions on Networking, vol. 29, no. 6, pp. 2413-2424, Dec. 2021.
- S. Sasi, V. Lalitha, V. Aggarwal, and B. S. Rajan, "Straggler Mitigation with Tiered Gradient Codes," IEEE Transactions on Communications, vol. 68, no. 8, pp. 4632-4647, Aug. 2020.
- A. Badita, P. Parag, and V. Aggarwal, "Sequential addition of coded tasks for straggler mitigation," in Proc. IEEE Infocom, Jul 2020.
- A. Badita, P. Parag, and V. Aggarwal, "Optimal Server Selection for Straggler Mitigation," IEEE/ACM Transactions on Networking, vol. 28, no. 2, pp. 709-721, April 2020.
Blockchain:
Blockchain is a distributed ledger with wide applications. Due to the increasing storage requirement for blockchains, the computation can be afforded by only a few miners. Sharding has been proposed to scale blockchains so that storage and transaction efficiency of the blockchain improves at the cost of security guarantee. We propose a new protocol, Secure-Repair-Blockchain (SRB), which aims to decrease the storage cost at the miners.
- Divija Swetha Gadiraju, V. Lalitha, and Vaneet Aggarwal, "An Optimization Framework based on Deep Reinforcement Learning Approaches for Prism Blockchain," IEEE Transactions on Services Computing, vol. 16, no. 4, pp. 2451-2461, 1 July-Aug. 2023
- Divija Swetha Gadiraju, V. Lalitha, and Vaneet Aggarwal, "Secure Regenerating Codes for Reducing Storage and Bootstrap Costs in Sharded Blockchains," in Proc. IEEE International Conference on Blockchain, Nov 2020
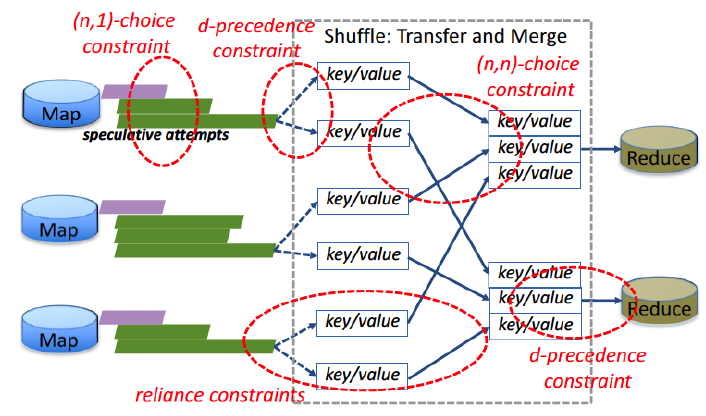
Framework for Interdependent Task Scheduling:
Distributed computing applications are becoming increasingly sophisticated and heterogeneous, often involving a collection of highly dependent data-processing tasks and network flows that must work in concert to achieve mission-critical objectives. Traditional techniques that are agnostic to such interdependence do not perform well in optimizing these collections, because resource management is largely framed as an optimization of individual task- or flow-level metrics. In this work, we model different dependence constraints between the different tasks including precedence, fractional precedence, and approximate computing. As an example, the figure alongside shows different forms of constraints for a MapReduce job. With these models of task dependence, we have proposed efficient scheduling strategies, with their performance guarantees.
- V. Aggarwal, T. Lan, and D. Peddireddy, "Preemptive Scheduling on Unrelated Machines with Fractional Precedence Constraints," Journal of Parallel and Distributed Computing, Volume 157, November 2021, Pages 280-286.
- V. Aggarwal, T. Lan, S. Subramaniam, and M. Xu, "On the Approximability of Related Machine Scheduling under Arbitrary Precedence," IEEE Transactions on Network and Service Management, vol. 18, no. 3, pp. 3706-3718, Sept. 2021.
- R. Mao and V. Aggarwal, "NPSCS: Non-preemptive Stochastic Co-flow Scheduling with Time-Indexed LP Relaxation," IEEE Transactions of Networking and Service Management, vol. 18, no. 2, pp. 2377-2387, Jun 2021.
- V. Aggarwal and R. Mao, "Preemptive Scheduling for Approximate Computing on Heterogeneous Machines: Tradeoff between Weighted Accuracy and Makespan," Information Processing Letters, Volume 153, January 2020.
- R. Mao, V. Aggarwal, and M. Chiang, "Stochastic Non-preemptive Co-flow Scheduling with Time-Indexed Relaxation," in Proc. Infocom Workshop (International Workshop on Big Data in Cloud Performance (DCPerf)), Apr 2018.
Multicast Queue and Coded Caching:
Caching plays a crucial role in networking systems to reduce the load on the network and is commonly employed by content delivery networks (CDNs) in order to improve performance. We consider the concept of coded caching, where coded caching and delivery schemes tailored towards systems are proposed in the scenario where the library is distributed across multiple servers, possibly with some redundancy in the form of maximum distance separable (MDS) erasure codes. We also note that the concept of coded caching require multiple request in a small time-interval, which results in loss in performance in realistic queueing systems. We consider the transfer of files using a multicast queue which exploits the broadcast nature of the queue. We analyze such a multicast queue for the first time in the literature, and show that a direct use of coded caching may not have gains as compared to the use of multicast queue alone.
- Mahadesh Panju, Ramkumar Raghu, Vinod Sharma, Vaneet Aggarwal, and Rajesh Ramachandran, "Queueing Theoretic Models for Uncoded and Coded Multicast Wireless Networks with Caches," Accepted to IEEE Transactions on Wireless Communication, Jul 2021.
- Ramkumar Raghu, Pratheek Upadhyaya, Mahadesh Panju, Vaneet Aggarwal, and Vinod Sharma, "Scheduling and Power Control for Wireless Multicast Systems via Deep Reinforcement Learning," Entropy, Nov 2021; 23(12):1555.
- Mahadesh Panju, Ramkumar Raghu, Vaneet Agarwal, Vinod Sharma, and Rajesh Ramachandran, "Queuing Theoretic Models for Multicasting Under Fading," in Proc. IEEE WCNC, Apr 2019.
- Yimeng Wang, Yongbo Li, Tian Lan, and Vaneet Aggarwal, "DeepChunk: Deep Q-Learning for Chunk-based Caching in Data Processing Networks," IEEE Transactions on Cognitive Communications and Networking, Special Issue on Deep Reinforcement Learning for Future Wireless Communication Networks, vol. 5, no. 4, pp. 1034-1045, Dec. 2019.
- Tianqiong Luo, Vaneet Aggarwal, and Borja Peleato, "Coded caching with distributed storage," IEEE Transactions on Information Theory, vol. 65, no. 12, pp. 7742-7755, Dec. 2019.
- Eric Friedlander and Vaneet Aggarwal, "Generalization of LRU Cache Replacement Policy with Applications to Video Streaming," ACM Tompecs, Volume 4 Issue 3, August 2019.
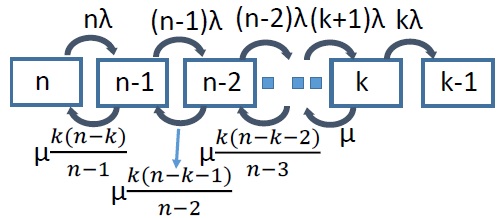
Erasure Codes in Distributed Storage for Effective Repair Bandwidth:
The reliability of erasure-coded distributed storage
systems, as measured by the mean time to data loss (MTTDL),
depends on the repair bandwidth of the code. Thus, efficient coding schemes that exploit repair bandwidths when a limited number of disks fail is important. We came with the first erasure code designs that achieve points between the two extremes on the repair bandwidth and storage trade-off that are asymptotically optimal. Further, the impact of optimal erasure code designs to mean time to data loss of the system is characterized. The figure alongside shows the state transition for a serial repair system accounting for repair in erasure coded systems.
- V. Aggarwal, "Reliability of k-out-of-n Data Storage System with Deterministic Parallel and Serial Repair," arXiv, Nov 2016.
- C. Tian, B. Sasidharan, V. Aggarwal, V.A. Vaishampayan, P.V. Kumar, "Layered Exact-Repair Regenerating Codes via Embedded Error Correction and Block Designs," in IEEE Transactions on Information Theory, vol.61, no.4, pp.1933-1947, April 2015
- V. Aggarwal, C. Tian, V. Vaishampayan, and R. Chen "Distributed Data
Storage Systems with Opportunistic Repair," in Proc. IEEE Infocomm 2014.
- C. Tian, V. Aggarwal, and V. Vaishampayan, "Exact-Repair Regenerating Codes Via Layered Erasure Correction and Block Designs," ArXiv Preprint, 2013
- C. Tian, V. Aggarwal, and V. Vaishampayan, "Exact-Repair Regenerating Codes Via Layered Erasure Correction and Block Designs," in Proc. IEEE ISIT, Jul. 2013
Delivering Deadline based services through Virtualization:
Virtualized cloud-based services can take advantage of statistical multiplexing across applications to yield
significant cost savings. However, achieving similar savings with real-time services can be a challenge. In these works, we seek to lower a providers costs for real-time IPTV services through a virtualized IPTV architecture and
through intelligent time-shifting of selected services. We provide a generalized framework
for computing the amount of resources needed to support multiple services, without missing the deadline for any
service. We construct the problem as an optimization formulation that uses a generic cost function. We consider
multiple forms for the cost function (e.g., maximum, convex and concave functions) reflecting the cost of providing
the service. The solution to this formulation gives the number of servers needed at different time instants to support
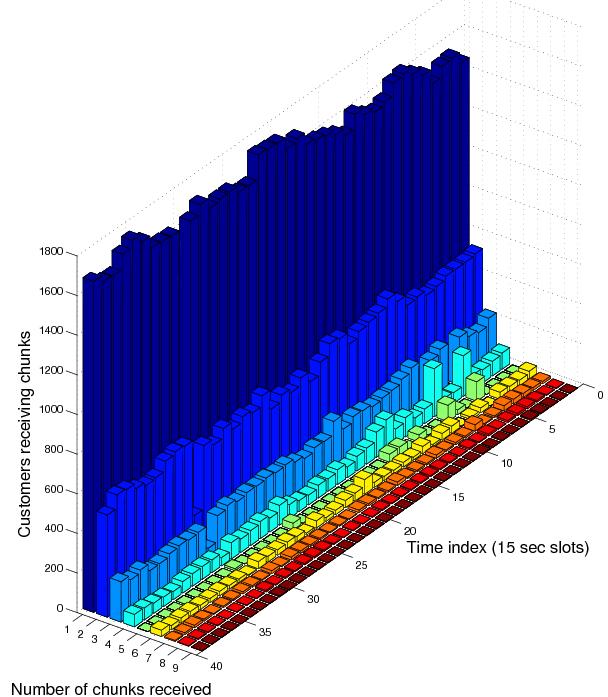
these services. Our results show about 31% improvement in costs for the deployed IPTV services. Further, Video on Demand (VoD) traffic can be delivered using multicast. I showed how IP multicast can be used to reduce load on the VoD server. This involved modeling the on-demand service and designing an optimal algorithm that minimizes server transmissions. Trace data from a deployed AT&T VoD service suggests that our approach reduces server bandwidth by as much as 65% compared to the standard architecture. The graphic is AT&T trace data showing the distribution of customers receiving different short video segments in a 10 minute interval.
- F. Stefanello, V. Aggarwal, L.S. Buriol, and M.G.C. Resende, "Hybrid
Algorithms for Placement of Virtual Machines across Geo-Separated Data Centers," Journal of Combinatorial Optimization, Volume 38, Issue 3, pp 748-793, Oct 2019.
- F. Stefanello, L.S. Buriol, V. Aggarwal, and M.G.C. Resende, "A New Linear Model for Placement of Virtual Machines across Geo-Separated Data Centers," in Proc. Anais do XLV Simposio Brasileiro de Pesquisa Operacional, Aug.
2015.
- F. Stefanello, V. Aggarwal, L.S. Buriol, J.F. Goncalves, and M.G.C. Resende, "A Biased Random-key Genetic Algorithm for Placement of Virtual Machines across GeoSeparated Data Centers," in Proc. Genetic and Evolutionary Computation Conference (GECCO), pp. 919-926, Jul.
2015.
- V. Aggarwal, V. Gopalakrishnan, R. Jana, K. K. Ramakrishnan
and V. Vaishampayan, "Optimizing Cloud Resources for Delivering IPTV Services through Virtualization," R-letters, vol. 4, no. 4, pp.
13-14, Aug. 2013.
- V. Aggarwal, V. Gopalakrishnan, R. Jana, K. K. Ramakrishnan
and V. Vaishampayan, "Optimizing Cloud Resources for Delivering IPTV Services through Virtualization," IEEE Transactions on Multimedia, special issue on Cloud-Based Mobile Media: Infrastructure,
Services, June 2013.
- W. Pang, P. Zhang, T. Lan, and V. Aggarwal, "Datacenter Net Prot Optimization with Deadline Dependent Pricing," in Proc. IEEE Conference on Information Sciences and Systems (CISS), Mar 2012.
- V. Aggarwal, V. Gopalakrishnan, R. Jana, K. K. Ramakrishnan
and V. Vaishampayan, "Optimizing Cloud Resources for Delivering IPTV Services through Virtualization," in Proc. IEEE International Conference on Communication Systems and Networks (COMSNETS), Jan 2012.
- V. Aggarwal, X. Chen, V. Gopalakrishnan, R. Jana, K. K. Ramakrishnan
and V. Vaishampayan, "Exploiting Virtualization for Delivering Cloud-based IPTV Services," in Proc. IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Apr 2011.
Home